-

In diesem Beitrag schauen wir uns an, warum die Welt der LLMs so „unzuverlässig“ ist und mit welchen Strategien man eine hohe Verlässlichkeit erreichen kann.
-
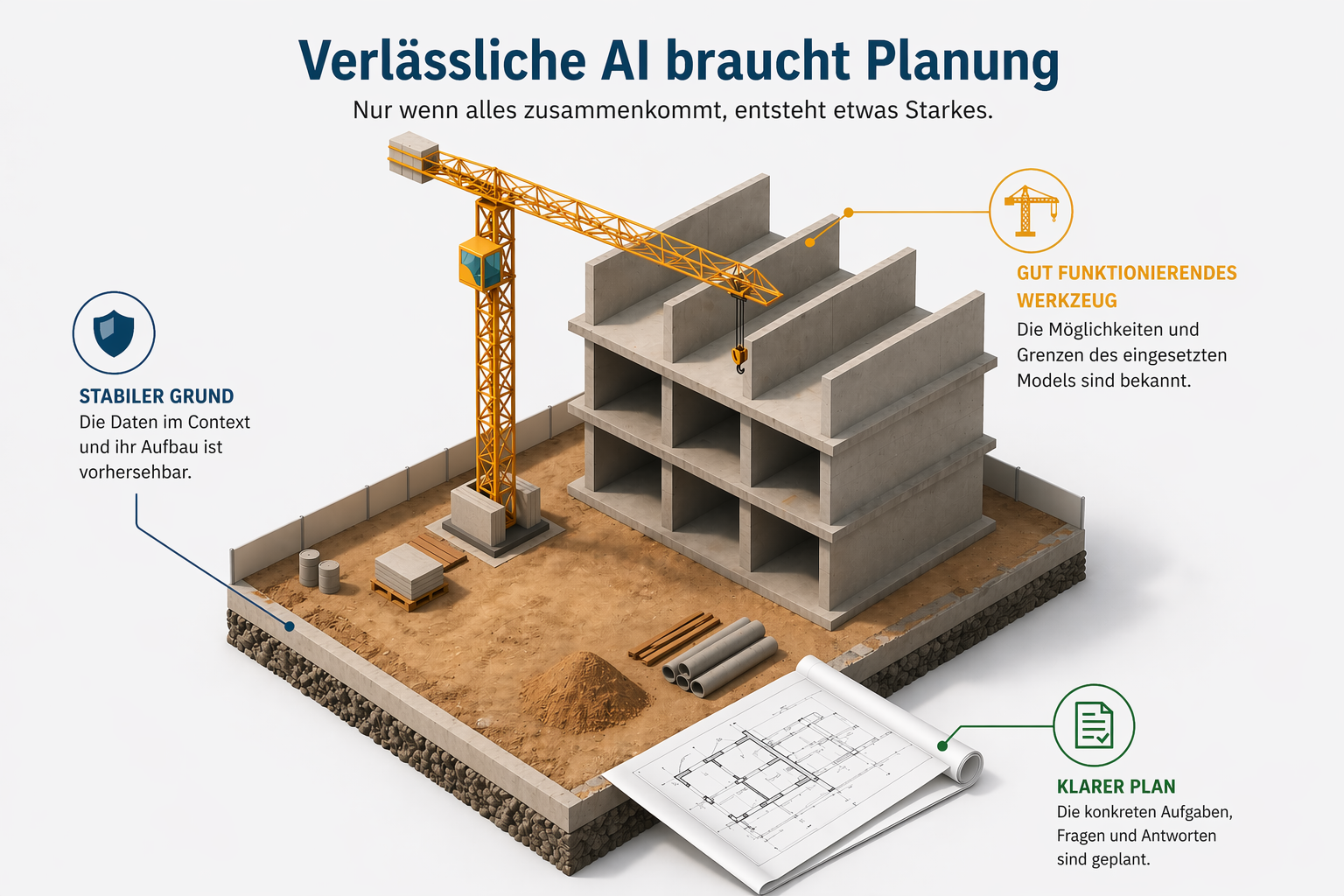
In diesem Beitrag wollen wir die drei wesentlichen Bausteine vorstellen, die man benötigt, um tatsächlich verlässliche, sichere AI zu erreichen.
-

Platon kritisierte die Schrift, weil sie keinen echten Dialog ermöglicht – und damit kein echtes Verständnis. Large Language Models wirken wie die Lösung: reaktiv, iterativ, adaptiv. Aber der Schein trügt. Wer AI-Systeme zuverlässig einsetzen will, braucht mehr als gute Outputs – er braucht einen Prozess, der das System systematisch hinterfragt. Ein Gedanke, der auch den…
-

Wenn ein Kunde fragt, was ihm nach Tarifwechsel, Promo-Gutschrift und Störung zusteht – scheitert klassische KI-Suche. Reasoning-Modelle lösen genau solche komplexen Mehrschritt-Fragen: durch iteratives Denken, gezielte Quellenverknüpfung und transparente Begründung.
-

Eigentlich sind wir gewohnt, Bildern und Videos zu vertrauen. „Seeing is believing“ ist ein geflügeltes Wort und drückt diese Erfahrung gut aus. DeepFakes erschüttern diese Erfahrung zunehmend. Daher wird es immer wichtiger zu verstehen, woran man denn DeepFakes erkennen kann. Wir haben uns damit beschäftigt und dafür ein paar Tipps beschrieben.
-

Immer mehr Anwendern wird klar, dass Testen zum Geschäft gehört, sollen GenAI Anwendungen verlässlich sein. Und …. richtig verlässlich sind sie sowieso nie – oder doch? In diesem Beitrag zeigen wir, wie durch ein komplexitätsbasiertes Testdesign auch 100% Verlässlichkeit erreicht werden können und dennoch Aufwand gespart wird.
-

Die richtige Frage bekommt eher die richtige Antwort als die falsche – was wie eine Binsenweisheit klingt kann bei Wissensdatenbanken echt ein Thema werden. Wir schauen uns in dem Beitrag näher an, wie man für die richtige Frage sorgen kann.
-

In einem Paper für die ICLR 2026 haben einige Wissenschaftler eine bemerkenswerte Interpretation des Themas „Halluzinationen“ vorgestellt. Das fanden wir so spannend und nützlich, dass wir das in einem etwas verständlicheren Artikel nochmal beschreiben und erklären wollten.
-

GPT 5.4 ist ein wichtiger Schritt für AI – und wir interessieren uns für die Verlässlichkeit von AI im Service. Daher mussten wir einfach mal testen, was GPT 5.4 da bietet.
-

Mit Reasoning ist es möglich, dass ein System nicht nur Texte wiederholt, sondern selbstständig Antworten aus einem Wissensbestand ableitet, und damit den Redaktionsbedarf drastisch reduziert. Wer Reasoning produktiv einsetzen möchte, muss verstehen, wie es funktioniert und wo seine Grenzen liegen. Dieser Beitrag gibt dazu praxisnahe Orientierung.