
Ein hoher Prozentsatz der AI Projekte klagt über die relative Unzuverlässigkeit der implementierten Agenten. Gerne wird das mit dem grundsätzliches Problem der Technik verargumentiert, da LLMs eben einen probabilistischen Charakter haben.
Die bestehende Unsicherheit führt zu einem erhöhten Testbedarf, und tatsächlich gibt es zunehmend Test- und Evaluierungstools. Test-Tools sind wir auch von anderen Anwendungen gewohnt, insofern scheint das bekannt. Jedoch muss ein probabilistisches Tool eben auch statistische Tests durchlaufen.
In der IT waren wir gewohnt, jeden Testcase einmal zu durchlaufen. Wenn alle Testcases funktionieren, dann ist die implementierte Funktion in Ordnung. Werden jedoch Anwendungen getestet, die auf Statistik beruhen, dann ist es vorbei mit dieser einfachen Welt. Nur weil ein UseCase 100 mal funktioniert hat bedeutet das noch lange nicht, dass der 101ste auch erfolgreich sein wird.
In diesem Beitrag schauen wir uns an, warum die Welt der LLMs so „unzuverlässig“ ist und mit welchen Strategien man eine hohe Verlässlichkeit erreichen kann.
Betrachtet man diese Problematik näher, dann lässt sie sich auf drei Kernthemen detaillieren:
LLMs weisen ein nicht lineares Verhalten auf
In manchen Fällen führen kleine Veränderungen der Eingabe auch nur zu kleinen Veränderungen der Ausgabe. LLMs hingegen sind sehr „sprunghaft“, schon kleine Veränderungen der Eingabe können zu großen Veränderungen der Ausgabe führen. Daher nennt man sie ja auch „nicht-linear“ (wobei sie da nicht alleine sind. Tatsächlich ist Linearität bei vielen Systemen nur eine Vereinfachung, die maximal bereichsweise zutrifft 😊).
Man mag das für die Testsituation bei LLMs als Problem betrachten. Auf der anderen Seite wären LLMs aber ohne diese Eigenschaft nicht in der Lage, mit Sprache umzugehen. Denn ändert sich Sprache nur ein bisschen (Ein Komma hier, ein „nicht“ dort…) kann die Bedeutung eines Satzes vollkommen geändert sein. Ohne dieses Nicht-Linearität könnten Sprachmodelle diese Eigenschaft von Sprache nicht abbilden. Wir werden daher nicht umhinkommen, mit dieser Eigenschaft umzugehen.
Sprache ist extrem vielfältig
Das „Problem“ liegt also nicht nur in der Technik. Wir müssen uns klar machen, dass Sprache eine extreme Varianz bietet, was für uns im Alltag zwar Probleme schaffen kann, oft aber auch einen Reichtum bietet, der ja den hohen Wert sprachlicher Fähigkeiten ausmacht.
Soll jedoch ein sicheres und testbares System geschaffen werden, dann müssen wir mit dieser Herausforderung umzugehen wissen.
Hohe Komplexität führt zu noch mehr Varianz
LLMs sind extrem leistungsfähig. Allerdings muss man auch berücksichtigen, dass Anwender dann eben noch komplexere Fragen stellen. Fragen, die z.B. auch noch Hintergrundwissen benötigen oder auch Schlussfolgerungsfähigkeiten. Und dann gehen diese Fragen und Aufgaben schnell über das Niveau hinaus, das von dem jeweiligen LLM sicher geboten werden kann. Oder anders ausgedrückt: Die Varianz bzw. die Qualität der Aufgabenerledigung eines LLMs ist immer auch eine Funktion der Komplexität der Aufgabe. Je komplexer die Aufgabe, desto höher ist die Wahrscheinlichkeit einer falschen Beauskunftung. Das Berücksichtigen der Aufgabenkomplexität ist also ein wesentlicher Aspekt, möchte man eine vorhersehbare Qualität erreichen.
Testkonzepte in Unsicherheit
Die teilweise kritischen Projektergebnisse haben wie erwähnt zunehmend Evaluierungs- und Testtechnologien auf den Markt gebracht, die ein automatisiertes Testen der Anwendungen erlauben. Das ist auch absolut sinnvoll, denn wie erwähnt sind auch 100 Tests manchmal noch nicht aussagekräftig. Dies ist manuell kaum leistbar, daher ist eine Automatisierung immer zwingend.
Aber wie viele Tests benötigt man? Wie viele Tests benötigt man beispielsweise, um sicher zu wissen, dass die Fehlerquote unterhalb von 5% liegt? Oder unter 1%?
Hier kann man sich bei der Wahrscheinlichkeitsrechnung bedienen. Zieht man in Betracht, dass man ja nur messen kann, ob denn das Ergebnis richtig oder falsch war und kalkuliert man gleichzeitig ein, dass man z.B. zu 99,99% wissen möchte, dass die prognostizierte Qualität tatsächlich erreicht wird, dann benötigt man für eine maximal 5%ige Fehlerquote 180 erfolgreiche Tests. Für eine einprozentige Fehlerquote 917. Und für eine 99,9% Korrektheit der Antworten 9206!
Dabei gilt: Taucht auch nur ein einzige fehlerhafte Antwort auf, erhöht sich die Anzahl Tests. Und man muss voraussetzen, dass sich Testdaten und Produktionsdaten nicht grundsätzlich unterscheiden.
Beides ist in der Praxis eher nicht erreichbar. Und so versinkt ein Projekt gerne in umfangreichen Tests und man fragt sich dennoch, wann man denn das Ende der Fahnenstange erreicht hat und man sich sicher sein kann, das passende Niveau erreicht zu haben.
Statistische Prozess-Kontrolle als alternativer Ansatz zur Qualitätssicherung
Wie erwähnt ist das nicht-lineare Verhalten von LLMs keine Besonderheit. Gerade in der Fertigung treten ganz ähnliche Probleme auf. Und gerade in der Fertigung ist es aus Kostengründen absolut wichtig, die Fehlerquote verlässlich vorherzusagen oder Fehler komplett zu vermeiden (Null-Fehler-Produktion).
Der Ansatz hier besteht darin, die Standardabweichung in der Produktion so zu kontrollieren, dass die maximal zulässige Fehlertoleranz kaum erreicht werden kann.
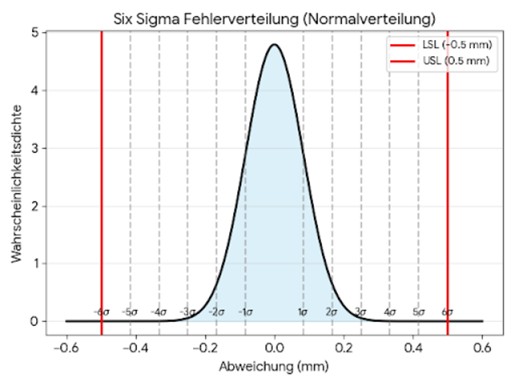
Beträgt bei einer maximal zulässigen (also zum Fehler führenden) Toleranz von 0,5 mm die Standardabweichung 0,0833mm, dann erreichen wir eine Fehlerrate von
0,0000002%!
Um die geringe Standardabweichung auch erreichen zu können muss der Prozess im Detail kontrolliert und im Griff sein. Daher nennt man das Konzept ja auch die statistische Prozesskontrolle.
Man kann das im Falle von AI schon mal als kluge Anregung verstehen. Ganz offensichtlich macht es Sinn, die komplette „Produktion“ (von Antworten oder das Ausführen von Aufgaben) zu betrachten und nicht einfach nur „den Chatbot“ oder die „AI“.
Den kompletten AI Prozess unter Kontrolle zu haben bedeutet:
- Zu wissen, wie genau die Qualitätsanforderungen aussehen
- Die zulässigen Aufgaben / Fragen in ihrer Form und ihrem Inhalt zu kennen
- Die tatsächliche Struktur der Inhalte im Context des LLMs zum Ausführungszeitpunkt kontrollieren zu können
- Dazu ist es auch notwendig, die zu verwendenden Inhalte der Form und dem Inhalt nach zu kennen
- Die Qualität des Modells zu kennen.
Schauen wir uns diese Punkte im Einzelnen an:
Definition der Qualitätsanforderungen
Antworten oder Aufgabenausführungen von AI Systemen sollen oft einfach „nicht falsch“ sein. Unklar bleibt dabei oft, was das nun wirklich bedeutet. Solange dies nicht eindeutig formuliert ist kann auch keine Qualitätsmessung durchgeführt werden.
Die „Richtigkeit“ einer Antwort umfasst :
- Den Mindestinhalt
- die ganze, vollständige korrekte Antwort
- Die Begrenzung
- Nur die vollständige Antwort, oder ist es auch erlaubt, weitere Aussagen zu treffen?
- Eine generelle Obergrenze, die die Antwort auch dann nicht überschreiten darf, wenn sie zusätzliche Aussagen enthalten kann.
- Die Form der Antwort
- Dies ist in der Praxis tatsächlich wichtig, um Antworten vernünftig zu verstehen oder weiter verarbeiten zu können.
Ist diese Form der Antwort definiert, dann ist man auch in der Lage, automatisch die Qualität der Antwort mithilfe eines LLMS zu prüfen (LLM as a judge), zumindest in den definierten Testfällen. Genau diesen Ansatz wählen auch Testautomatisierungswerkzeuge wie Promptfoo.
Die zulässigen Aufgaben und Fragen
Ein altes Sprichwort merkt an, dass ein Narr mehr fragen kann als 1.000 Weise beantworten können. Fragen sind erst einmal unbegrenzt. Kombiniert mit der Fabulierkunst der LLMs (meist als Halluzination bezeichnet) führen solche Fragen dann auch oft zu fehlerhaften Antworten. Daher ist es wichtig, Fragen zu begrenzen und zulässige Fragen auch auf eine bekannte Form zu normieren (das nennt man dann Kanonisierung). Das kann man beispielsweise mithilfe eines vorgeschalteten Agenten und einer passenden Ontologie machen (Sie finden hier eine gute Darstellung dazu).
Der Kontext und die Dokumente
Von Multiturn-Dialogen abgesehen ergibt sich der Inhalte des Context eines LLMs in der Regel aus der Aufgabe / Frage und den per RAG Architektur hochgeladenen Dokumenten. (Multiturn Dialoge betrachte wir hier der Einfachheit halber nicht).
Entscheidend sind daher die zu verwendenden Dokumente. Normalerweise heißt es an dieser Stelle, dass die zu verwendenden Dokumente „AI Ready“ sein sollen. Was natürlich eine richtige Anmerkung ist. Geht es jedoch um eine vorhersehbare Prozessqualität oder gar eine Null-Fehler-Produktion, dann bedeutet „AI Ready“ ein hohes Maß an Gleichartigkeit der Dokumente.
Hier greift auch wieder der Prozessvergleich: Man erreicht eine geringe Standardabweichung der Produktion durch Verwendung der immer gleichen Ölsorte, der immer gleichen Temperatur, einer hohen Stabilität der Abmessungen von Bauteilen etc.
Für den ebenfalls nicht-linearen AI Produktionsprozess gelten also dieselben Voraussetzungen: Es ist sicherzustellen, dass ein Dokument, das einen Tarif beschreibt immer vorhersehbar gleich aussieht. Ein Dokument, das einen Prozess oder eine Handhabung beschreibt, hat ebenfalls immer gleich auszusehen und dieselbe Struktur aufzuweisen. Es ist dabei also die Aufgabe des Wissensmanagements, für eine qualitativ gesicherte und einheitliche Zulieferung von Inhalten zu sorgen, um die angestrebte Qualität wirklich erreichen zu können.
Welche Parameter kann man prüfen, um die Vergleichbarkeit von Dokumenten zu ermitteln
Um eine einheitliche Aufgabenkomplexität erreichen zu können, benötigt man eine Kanonisierung der Fragestellung. Zudem müssen die verwendeten Dokumente Einheitlichkeit in Aufbau und Struktur aufweisen.
Wesentliche Anforderungen sind:
- Die Größe der Dokumente (bzw. Blöcke für den Kontext) darf nicht zu sehr variieren, da die Menge der Token im Kontext immer auch ein Komplexitätsthema ist.
- Informationen zu den beauskunfteten Themen sollten nicht zu sehr bzw. zu unterschiedlich verteilt sein, da „needle in the haystack“ ebenfalls ein Komplexitätsaspekt darstellt.
- Mehrschrittige logische Verknüpfungen stellen ebenfalls Komplexität dar und sollten nicht zu sehr variieren.
- Rechnungen, formale Vorschriften und Aufgaben führen ebenfalls zu Komplexität.
- Transferleistungen der Eingabe zum Dokumententext sind auch als Komplexität zu berücksichtigen.
Diese Parameter sollten bei den verwendeten Inhalten auf einem in etwa gleichen Niveau liegen oder das getestete Niveau nicht überschreiten, dann kann eine einheitliche Qualität erreicht werden.
Generell sollte und kann man vermeiden, dass Irritierendes und Ähnliches, aber nicht mit dem Thema verknüpftes in den Dokumenten ist. Ebenso sind Aussagen zu vermeiden, die zum Beispiel früher gültig waren. Oder auch Inhalte, die eigentlich zu anderen Domänen gehören oder widersprüchlich sind. Diese Punkte aber sind genereller Natur und können über Datenpflege und Datenauswahl erreicht werden.
Die Fähigkeit des eingesetzten Modells und statistische Tests
Wie schon ausgeführt, gibt es eine reziproke Korrelation zwischen Komplexität und Zuverlässigkeit. Wir haben nun schon gesehen, dass die Zuverlässigkeit eines Agenten direkt mit der Vorhersehbarkeit der Aufgabe zusammenhängt, und damit natürlich auch mit einer stabilen Aufgabenkomplexität.
Und in jedem Fall ist zu klären, ob das eingesetzte Modell bei der angedachten Qualität und Komplexität einsetzbar ist. Klar ist, dass das zu testen ist.
Da wir uns im Bereich der statistischen Prozesskontrolle befinden, lösen wir das Problem auch mit diesem methodischen Ansatz. Statt auf eine Menge Tests und ein Vertrauensintervall zu setzen, gehen wir von einer Standardabweichung der „Fertigung“ aus.
Und da taucht ein Problem auf: Wenn wir wie oben einfach nur „richtig/falsch“ Tests durchführen, haben wir keine Möglichkeit für die Messung einer Standardverteilung.
Die Herausforderung ist also, eine alternative oder zusätzliche Messung einer Standardverteilung zu definieren.
Schauen wir uns das in einem Beispiel an:
Wir möchten in einem System korrekte Antworten auf Fragen zu einem Leasingvertrag. Damit ist der Kontext erstmal gegeben, die Fragestellungen können jedoch verschiedene Komplexität annehmen. In diesem Beispiel variieren wir die Komplexität der Frage darüber, wie viele Aussagen des Leasingvertrages benötigt werden, um die Antwort zu erstellen. (Natürlich gäbe es auch andere „Komplexitätsschrauben“, beispielsweise das Mappen einer Alltagssprache zu einer Vertragssprache, die Erkennung von komplexen Situationen und das Mapping in die Vertragsaspekte etc.)
Wir definieren vier unterschiedliche Komplexitätslevels, um die Stabilität bzw. Standardabweichung zu ermitteln. Wir testen die beiden Modelle GPT 5.5 und GPT 5.4 nano.
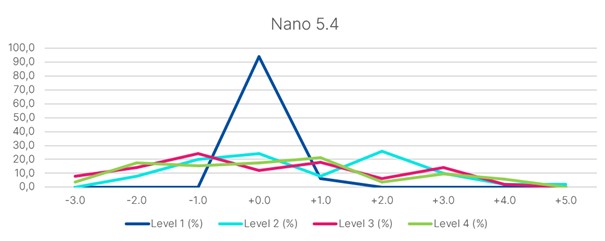

Zusätzlich zu der eigentlichen Frage lassen wir das Modell die Frage beantworten, wie viele Sätze für die Erstellung der Antwort benötigt wurden. Auf der Abbildung ist die richtige Anzahl Sätze in jedem Level bei der 0. Die Abweichungen nach Links und Rechts zeigen den Prozentsatz der Antworten auf, die mit weniger oder mehr Sätzen erstellt wurden.
Was man einfach erkennen kann:
Beide Modelle sind im Fall des Level 1 absolut zuverlässig. Es gibt keinerlei Schwankung. Betrachtet man übrigens die tatsächlichen Antworten und definiert die richtige Antwort als „korrekt, vollständig und ohne Zusatzinformation“, dann sind 100% der Antworten korrekt.
Bei Level 2 und 3 wird die Varianz schon deutlich höher. Tatsächlich sind die Antworten bei beiden Modellen korrekt und vollständig. Allerdings produziert GPT 5.4 nano zunehmend irrelevante Zusatzinformationen.
Das kann man ganz gut mit der Standardabweichung der Anzahl Zeichen im Text verdeutlichen:
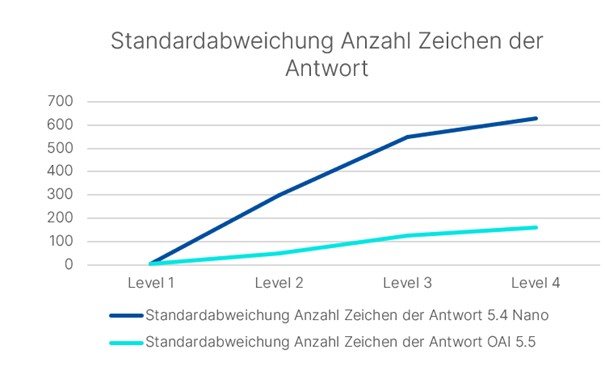
Schon bei Level 2 schwankt die Antwortlänge bei 5.4 Nano um rund 300 Zeichen, 5.5 bleibt hingegen zweistellig.
Bei Level 4 wird die Schwankungsbreite bei GPT 5.4 Nano ziemlich groß. Betrachtet man nun hier die Antwortqualität, dann stellt man fest, dass alle Antworten bei beiden Modellen korrekt sind, jedoch bei 5.4 Nano sind die Antworten in 22% der Fälle unvollständig. Bei 5.5 sind auf Level 4 alle Antworten korrekt und vollständig.
Was sagt das nun für die Verwendbarkeit der Modelle für die geforderte Komplexität und Antwortqualität aus?
Im gegebenen Fall wäre sowohl Nano 5.4 als auch 5.5 in beiden Fällen mit einer rechnerischen Fehlerquote von 0% für Level 1 anwendbar.
Erwartet man nicht nur korrekte und vollständige, sondern auch in der Form stabile (oft auch einfach verständliche) Antworten, dann ist 5.4 Nano für Level 2 nicht mehr verwendbar.
(Korrekterweise müsste man hier natürlich eine obere und untere Grenze definieren, um die tatsächliche Fehlerwahrscheinlichkeit zu errechnen. Allerdings lohnt sich das bei diesem Beispiel nicht wirklich 😊).
Erwartet man nur vollständige Antworten, dann stellen wir fest, dass Nano 5.4 sowohl bei Level 2 als auch bei Level 3 richtige Antworten geliefert hat.
Nehmen wir allerdings an, dass bei einer Anzahl von -4 Sätzen ein Fehler aufgetreten wäre, dann würden wir bei Level 2 mit einer Fehlerwahrscheinlichkeit von 0,2% zu rechnen haben und bei Level 3 liegt die Fehlerwahrscheinlichkeit bei 2%.
Mit GPT 5.5 hingegen ist die Fehlerwahrscheinlichkeit auch bei Level 3 und 4 vernachlässigbar.
Tatsächlich wurden hier nur 50 Tests gemacht, die Aussage hingegen ist ziemlich verlässlich und stabil – wenn das Umfeld ebenfalls stabil ist.
Anmerkung: Die Fragekomplexität würde man in diesem Fall nun über einen eingehenden Klassifikator prüfen und unzulässige Fragen ablehnen oder zu einer einfacheren Formulierung auffordern.
Anforderungen an Qualitätstests in der statistischen Prozesskontrolle
Wie das Beispiel gezeigt hat, erfordert die statistische Qualitätskontrolle immer die Messung einer Standardabweichung. Das oft verbreitete „korrekt“ / „nicht korrekt“ reicht für diese Zwecke nicht aus.
Wir haben in dem obigen Beispiel schon zwei mögliche Messwerte kennengelernt, die Anzahl Sätze aus dem Basistext und die Standardabweichung der Antwortlänge.
Weitere Varianten sind natürlich denkbar, beispielsweise
- Definition einer Vorlage für die Antwort und das Maß der Formeinhaltung (z.B. die Reihenfolge der Antworten oder ähnliches)
- Man lässt das System zusätzlich zur Antwort eine Begründung seiner Antwort erstellen und überprüft die Längenvarianz der Begründung
- Ein ganz interessanter Punkt ist der Logprob Wert. Viele LLMs geben bei ihrer Auswahl die Wahrscheinlichkeit des nächsten Tokens an. Bei manchen Prozessen ist dieser Wert nicht verwendbar (da die folgende Antwort zu lange und durch den jeweiligen Logprob Wert nicht ausreichend bestimmt), bei einfachen Klassifizierungsprozessen macht das durchaus Sinn.
Mit einigem Nachdenken findet man bei jedem Fall einen messbaren Skalar, der es erlaubt, die Standardabweichung zu messen und damit den Grad der Kontrolle des Produktionsprozesses zu ermitteln.
Wie behält man Komplexität im Griff
Wie wir sehen, ist die Komplexität eines Verarbeitungsschrittes mit einem LLM ein wichtiges Thema für die Verlässlichkeit des Systems.
Was aber kann man machen, um eine Anwendung mit hoher Komplexität in den Griff zu bekommen?
Schauen wir uns das Beispiel eines Agenten an, der einfach nur eingehende Fragen mit hoher Sicherheit klassifizieren soll. Im Test stellt man fest, dass dieser Agent mit der Komplexität nicht zurechtkommt. Zu unterschiedlich sind die Fragen, zu wenig abgegrenzt die zu wählenden Klassen.
Ist die Komplexität zu hoch muss man eben die Komplexität durch Aufsplitten in Einzelaufgaben reduzieren.
Statt also eines Klassifizierungsagenten kann es eine Idee sein, diesen Agenten in drei einzelne Verarbeitungsschritte bzw. drei Agenten aufzuteilen:
- Der erste Agent ermittelt, ob die Frage überhaupt zulässig ist.
- Der zweite kanonisiert die Frage
- Der dritte führt dann die Klassifikation durch.
Die ersten beiden Agenten verwenden für ihre Aufgabe auch nicht irgendwelche Originaldokumente, sondern entsprechende Ontologien bzw. Knowledge Graphs.
Nun stellt sich noch die Frage nach der Verlässlichkeitsmessung dieser Funktion.
Da der erste Agent ja nur ein „richtig“ oder „falsch“ misst ist zu klären, welche Qualitätsanforderungen wir haben.
Dabei legen wir fest:
False negative ist in Ordnung. Weist der Agent eine eigentlich zulässige Frage als falsch an, können wir damit leben.
False positive ist nicht zulässig, hier wollen wir 0% nicht-zulässige Fragen durch das System lassen.
Hier macht es dann Sinn mit Logprob zu arbeiten. Nur dann, wenn der Agent sich sicher ist, dass die Frage passt, soll er sie als zulässig durchlassen.
Bei der Kanonisierung der Frage können wie das Einhalten einer vorgegebenen Form als Qualitätsmaß nehmen, das wir auf eine Skala abbilden. Damit können wir die Stabilität der Fertigung gut messen.
Der dritte Agent soll uns zu der Klasse noch eine kurze Begründung anführen, die eine Form einzuhalten hat, so dass wir auch hier wieder eine Messung dieses Teilagenten durchführen können.
Fazit
Die statistische Prozesskontrolle ist ein Weg, um auch bei AI Prozessen hohe Qualität im Null-Fehler Bereich zu erreichen. Dabei setzt sie eher auf „Teilen und Herrschen“ als auf das massive Testen aller Eventualitäten und ist damit viel effizienter als bisherige Lösungsstrategien.
Schreibe einen Kommentar