Verlässliche AI-Agenten
trotz Halluzinationen
Large Language Models revolutionieren die Automatisierung. Dennoch scheitern viele AI-Agenten an fehlender Verlässlichkeit. Daher haben wir RELY_QA ins Leben gerufen.
Wir helfen Dir, kostenoptimierte und halluzinationsfreie Agenten zu bauen. Damit Du weißt, welches LLM das passende ist liefern wir aktuelle Benchmarks gerade für den RAG Fall.
⚠️
Die Herausforderung
Generative AI ermöglicht die Automatisierung komplexer Prozesse. Diese waren bisher undenkbar. Jedoch erreichen viele Implementierungen nicht die nötige Verlässlichkeit.
Halluzinationen treten regelmäßig auf. Außerdem fehlt oft die Vollständigkeit der Antworten. Und so scheitern viele AI-Projekte in der Produktion.
Darüber hinaus gibt es weitere Probleme. Beispielsweise übertragen Modelle Regeln auf unpassende Fälle, was zu falschen Angaben führt. Dies nennt man Overgeneralization.
✅
Unsere Lösung
Mit RELY_QA helfen wir, den GenAI-Einsatz verlässlich zu machen. Dabei setzen wir auf systematische Tests. Diese prüfen kritische Edge Cases gründlich.
So kennst Du die Grenzen genau. Und Du kannst das Verhalten des Modells vorhersehen. Damit kannst Du genau das Modell auswählen, das zu Deinen Anforderungen und Deinem Budget passt.
Unsere Benchmarks zeigen die tatsächliche Performance, damit Du teure Fehler vermeiden kannst. Damit machen wir es auch möglich, das jeweils günstigste LLM zu verwenden.
Laut aktueller Forschung von Anthropic sind systematische Tests entscheidend. Ebenso betont OpenAI in ihrer Dokumentation die Bedeutung von Benchmarks.
Die 4 Grundbausteine verlässlicher AI-Agenten
Um verlässliche Arbeitsergebnisse von GenAI zu erhalten, musst Du an vier Bereichen arbeiten. Diese sind fundamentale Voraussetzungen. Daher solltest Du keinen Aspekt vernachlässigen.
🎯
1. Tool Proficiency
Es muss bekannt sein, wie sich das LLM verhält. Welche Fehlerquoten sind zu erwarten? Dies variiert je nach Aufgabe.
Du musst die Grenzen kennen. Nur dann kannst Du das Verhalten steuern. UNd damit wird das System verlässlich.
❓
2. Festgelegte Fragen
Die zulässigen Fragen müssen definiert sein. Sonst beantwortet das System alles. Dies führt zu Halluzinationen.
Daher solltest Du die Fragen kontrollieren. Lasse nicht jede Frage zu. Damit erhöhst Du die Zuverlässigkeit erheblich.
🔧
3. Context Engineering
LLMs verarbeiten nur den aktuellen Context. Nichts anderes. Deshalb müssen sie die richtigen Informationen bekommen.
Diese Planungsarbeit nennt sich Context Engineering. Sie ist entscheidend für korrekte Antworten. Das ist eine spannende Disziplin für Dich.
📚
4. Information Architecture
LLMs benötigen tatsächliches Wissen. Keine Annahmen. Sie brauchen vollständiges und verlässliches Wissen.
Deshalb ist ein guter Redaktionsprozess wichtig. Hohe Content-Qualität ist unverzichtbar. Nur so liefert der Agent richtige Ergebnisse.
Weitere Informationen zu diesen Konzepten findest Du in der OpenAI Prompt Engineering Dokumentation sowie in wissenschaftlichen Arbeiten zum Thema LLM Reliability.
📊
Detaillierte Benchmark-Analysen
Vergleiche führende LLMs über 5 kritische Edge Cases. Wir liefern detaillierte Auswertungen. Erhalte zudem konkrete Handlungsempfehlungen.
Unsere Tests basieren auf realen Anwendungsfällen. Daher sind die Ergebnisse praxisrelevant. Für Deine fundierte Entscheidung.
Die 5 kritischen Edge Cases
Diese Szenarien entscheiden über Erfolg oder Scheitern. Jedes LLM verhält sich unterschiedlich. Daher solltest Du diese Edge Cases kennen.
Außerdem steigt die Fehlerrate bei größerem Context. Infolgedessen sind systematische Tests unverzichtbar.
⚡
Overgeneralisation
LLMs übertragen manchmal Regeln auf unpassende Fälle. Beispielsweise wird eine Regelung für Führerscheine auch auf Personalausweise angewendet. Dies ist jedoch falsch.
Daher musst Du dieses Verhalten im Auge haben. Mini-Modelle sind anfälliger. Größere Modelle liefern bessere Ergebnisse.
✓
Completeness
Eine richtige Antwort ist nicht immer vollständig. Manchmal fehlen wichtige Details. Infolgedessen treffen Nutzer falsche Entscheidungen.
Außerdem variiert die Vollständigkeit zwischen Modellen. Daher testen wir diesen Aspekt systematisch.
⚖️
Counterfactual Robustness
Widersprüche in Daten sind häufig. Manche LLMs ignorieren diese. Andere erkennen sie zuverlässig.
Du solltest wissen, wie Dein Modell reagiert. Dies vermeidet fehlerhafte Ausgaben.
🔗
Information Integration
Komplexe Antworten erfordern mehrere Informationsquellen. Diese müssen kombiniert werden. Nicht alle Modelle beherrschen dies gleich gut.
Deshalb testen wir diese Fähigkeit gezielt. Dann weißt Du, welches Modell passt.
🚫
Negative Rejection
Manchmal liegen keine Daten vor. Dann sollte das LLM dies eingestehen. Stattdessen erfinden manche Modelle Antworten.
Daher ist diese Fähigkeit kritisch. Wir prüfen sie in allen Tests.
Häufig gestellte Fragen
Was sind Edge Cases bei Large Language Models?
Edge Cases sind Grenzfälle, in denen LLMs häufig Fehler machen. Diese treten auf, wenn das Modell an seine Grenzen stößt. Beispielsweise bei widersprüchlichen Informationen. Oder wenn keine Daten vorliegen. Folglich sind diese Tests essentiell.
Warum sind Benchmarks für AI-Agenten wichtig?
Benchmarks zeigen die tatsächliche Performance. Ohne Tests weiß man nicht, wie sich das Modell verhält. Infolgedessen entstehen unvorhersehbare Fehler. Außerdem hilft es bei der Modellauswahl. Daher sind systematische Tests unverzichtbar.
Wie vermeidet man Halluzinationen bei GenAI?
Vollständig vermeiden kann man sie nicht. Jedoch kann man die Rate auf ein kontrolliertes und vorhersehbares Maß reduzieren. Wir beschrieben hier 4 Grundbausteine. Insbesondere Tool Proficiency ist wichtig. Und wenn Du dann auch noch die Fragen kontrollierst, dann hast Du das Risiko im Griff.
Welches LLM sollte ich für meinen Use Case wählen?
Das hängt von Deinen Anforderungen ab. Manche Use Cases brauchen hohe Genauigkeit. Andere benötigen schnelle Antworten. Daher sollten Sie Benchmarks nutzen. Diese zeigen die Performance pro Edge Case. Folglich findest Du das optimale Modell.
Was ist Context Engineering?
Context Engineering ist die gezielte Bereitstellung von Informationen. LLMs arbeiten nur mit dem aktuellen Context. Nichts anderes steht zur Verfügung. Deshalb musst Du die richtigen Daten liefern. Dies erfordert sorgfältige Planung. Context Engineering ist eine eigene, sehr erfolgreiche Disziplin.
Neueste Artikel & Updates
Erfahremehr über Fortschritte in Agentic AI. Außerdem veröffentlichen wir regelmäßig Test-Ergebnisse. Darüber hinaus teilen wir Best Practices.
-

Statistische Prozesskontrolle als Basis für erfolgreiche Qualitätssicherung in der AI
In diesem Beitrag schauen wir uns an, warum die Welt der LLMs so „unzuverlässig“ ist und mit welchen Strategien man…
-
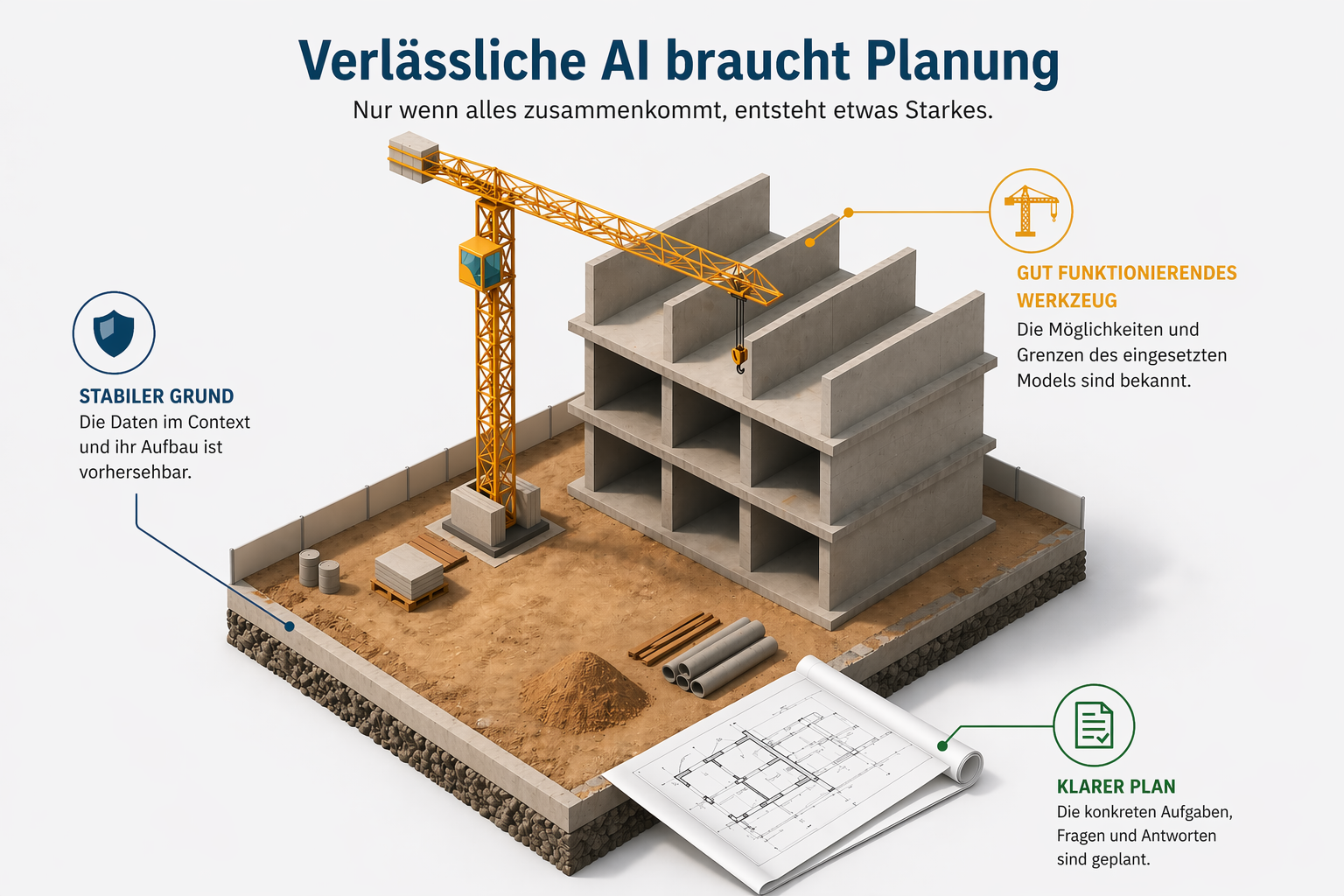
Verlässlichkeit und Vorhersehbarkeit – AI, auf die man sich verlassen kann
In diesem Beitrag wollen wir die drei wesentlichen Bausteine vorstellen, die man benötigt, um tatsächlich verlässliche, sichere AI zu erreichen.
-

Platon und das Problem mit KI-Antworten
Platon kritisierte die Schrift, weil sie keinen echten Dialog ermöglicht – und damit kein echtes Verständnis. Large Language Models wirken…
Bleibe auf dem Laufenden
Erhalte Updates zu neuen Benchmarks. Außerdem teilen wir Best Practices. Und Du bleibst immer uptodate!
Newsletter-Formular wird hier integriert