
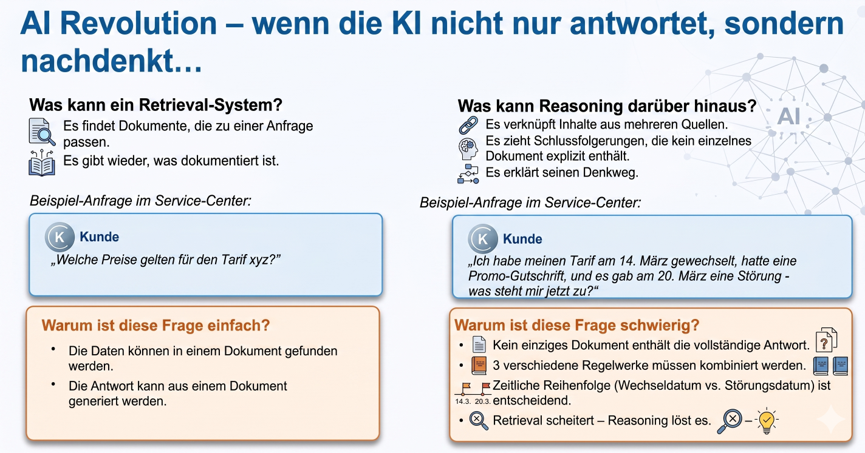
Stellen Sie sich vor, ein Kunde ruft im Service-Center an und fragt:
„Ich habe meinen Tarif am 14. März gewechselt, hatte vorher eine Promo-Gutschrift, und es gab am 20. März eine Störung – was steht mir jetzt eigentlich zu?“
Eine einfache Frage – aus Kundensicht. Aus KI-Sicht ist sie eine der schwierigsten Kategorien überhaupt: Keine einzige Antwort liegt dokumentiert vor. Die Antwort muss erst erarbeitet werden, durch das Verknüpfen mehrerer Regelwerke, unter Berücksichtigung von Datumsreihenfolgen und tarifspezifischen Klauseln.
Klassische KI-Suche scheitert hier. Reasoning löst es.
Was ist Reasoning – und was unterscheidet es von klassischer KI-Suche?
Viele KI-Systeme im Kundenservice arbeiten heute nach dem Prinzip Retrieval-Augmented Generation (RAG):
- Die Frage wird in einen Suchvektor umgewandelt.
- Die ähnlichsten Dokumente werden aus der Wissensdatenbank geholt.
- Diese Dokumente werden der KI als Kontext übergeben.
- Die KI formuliert daraus eine Antwort.
Das funktioniert hervorragend für direkte Fragen, die in einem einzigen Dokument beantwortet werden können. Bei der oben genannten Kundenfrage versagt RAG – weil die Antwort schlicht nicht existiert. Sie muss aus mehreren unabhängigen Regelwerken erst hergeleitet werden.
Ein Reasoning-basiertes System arbeitet fundamental anders. Es denkt iterativ: Es plant, holt gezielt Informationen, bewertet sie, stellt fest was noch fehlt, holt weitere Informationen – und formuliert erst dann eine Antwort.
| Eigenschaft | RAG | Reasoning |
|---|---|---|
| Dokumentenabruf | Einmalig, vor der Antwort | Iterativ, während des Denkens |
| Aufgabe selbst entscheiden | Nein – vorgegeben | Ja – eigenständig |
| Quellen verknüpfen | Nein | Ja |
| Zeitliche Einordnung | Nein | Ja |
| Denkweg sichtbar | Nein | Ja |
| Fehlende Infos erkennen | Nein | Ja |
Die Rolle von MCP: Wie das Modell auf Wissen zugreift
Was MCP ist
MCP (Model Context Protocol) ist ein offenes Protokoll, das einem KI-Modell erlaubt, externe Systeme strukturiert anzusprechen. Es ist im Kern wie eine API – aber speziell für den Einsatz durch KI-Agenten designed. Das Reasoning-basierte System bekommt nicht einfach ein Dokument übergeben. Es ruft aktiv Werkzeuge auf, holt sich genau das, was es gerade braucht, und entscheidet selbst, was als nächstes zu tun ist.
Im Kontext eines Knowledge-Management-Systems stehen dem Modell über MCP typischerweise Werkzeuge wie diese zur Verfügung:
search_knowledge_base(query, filters)
→ Suche in der Wissensdatenbank
→ Rückgabe: Liste von Dokumenten mit Titel, ID, Relevanz-Score
get_document(article_id)
→ Abruf eines spezifischen Artikels im Volltext
→ Rückgabe: Inhalt, Metadaten, Gültigkeitsdatum, Kategorie
list_documents(category, tags)
→ Auflistung aller Dokumente einer Kategorie
→ Nützlich, wenn das Modell nicht weiß, wonach es genau suchen soll
get_document_links(article_id)
→ Gibt verwandte Dokumente zurück (Querverweise aus der KB)
→ Hilft beim Navigieren durch zusammenhängende RegelwerkeDas Modell entscheidet selbst, welches Werkzeug es wann aufruft. Es bekommt keine Anweisung wie „Such nach Tarifwechsel“. Es analysiert die Kundenfrage und leitet daraus eigenständig ab, welche Suchen sinnvoll sind.
Der iterative Abrufprozess – am konkreten Beispiel
Am Beispiel der eingangs genannten Kundenfrage lässt sich der Prozess Schritt für Schritt nachvollziehen:
Runde 1 – Planung:
Das Modell analysiert die Frage und erkennt drei eigenständige Teilprobleme: Tarifwechsel-Regelung, Promo-Gutschrift-Bedingungen, Störungs-Entschädigung.
Runde 2 – Erster Abruf:
→ search_knowledge_base("Tarifwechsel Konditionen")
← Art. 4210 "Tarifwechsel-Regelung": "Ab dem Wechseldatum gelten die
Konditionen des neuen Tarifs. Bestehende tarifspezifische Vorteile
erlöschen mit Wirkung des Wechsels..."Runde 3 – Zweiter Abruf:
Das Modell hat aus dem ersten Dokument gelernt, dass „tarifspezifische Vorteile erlöschen“. Es fragt jetzt gezielt nach, ob Promo-Gutschriften darunter fallen:
→ search_knowledge_base("Promo Gutschrift Tarifwechsel Übertrag")
← Art. 4851 §7: "Promo-Gutschriften sind an den zum Zeitpunkt der Buchung
gültigen Tarif gebunden. Ein Übertrag ist ausgeschlossen."Runde 4 – Dritter Abruf:
Das Modell kennt jetzt das Wechseldatum (14.03.) und prüft, welche Störungsregel am 20.03. gilt – also im neuen Tarif:
→ search_knowledge_base("Störung Entschädigung Tarif")
← Art. 3012 §12: "Kunden erhalten bei bestätigter Netzstörung
von mehr als 2 Stunden eine Gutschrift von 15% des Tagesreisepreises."Runde 5 – Vollständigkeitsprüfung:
Alle drei Teilfragen sind beantwortet. Das Modell schließt die Reasoning-Schleife und formuliert eine strukturierte, begründete Antwort für den Service-Agenten.
Wie Dokumente gefunden und bewertet werden
Suchmethoden – je nach System unterschiedlich kombiniert
Moderne Knowledge-Management-Systeme bieten dem Reasoning-basierten System über MCP in der Regel mindestens zwei grundlegend verschiedene Suchmethoden an – manche Systeme auch mehr:
Semantische Suche (Embedding-basiert):
Frage und Dokumente werden in hochdimensionale Vektoren umgewandelt. Je ähnlicher zwei Vektoren, desto relevanter das Dokument. Vorteil: Findet auch Dokumente, die andere Formulierungen verwenden als die Frage (z.B. „Erstattung“ statt „Gutschrift“). Nachteil: Bei sehr spezifischen Begriffen wie Artikelnummern oder Paragraphen weniger präzise.
Volltextsuche (Keyword-basiert):
Klassische Suche nach exakten Begriffen. Ideal für Artikel-IDs, §-Verweise, Produktnamen und Datumsangaben. Auch Systeme, die keine semantische Suche unterstützen, können auf diese Weise sinnvoll eingebunden werden.
Das Modell wählt die verfügbare Methode je nach Suchanfrage – oder kombiniert beide, wenn das System es erlaubt.
Bewertungskriterien für gefundene Dokumente
Nicht jedes zurückgegebene Dokument wird verwendet. Das Modell bewertet jeden Treffer anhand mehrerer Kriterien:
Relevanz-Score: Jedes Dokument kommt mit einem Score aus der Suche (0–1). Das Modell berücksichtigt ihn, verwirft aber auch Dokumente mit hohem Score, wenn der Inhalt nach Lektüre nicht zur konkreten Teilfrage passt.
Gültigkeitsdatum: Gut gepflegte Knowledge-Management-Systeme speichern zu jedem Artikel Gültigkeitsbeginn und -ende. Das Modell prüft, ob das Dokument zum Zeitpunkt des Ereignisses gültig war. Ein veraltetes Dokument wird explizit als solches markiert oder ignoriert.
Widerspruchserkennung: Liefern zwei Dokumente gegensätzliche Aussagen, erkennt das Modell den Widerspruch und meldet ihn explizit – anstatt stillschweigend eine der Aussagen zu verwenden.
Was passiert, wenn kein Dokument gefunden wird?
Das ist ein wichtiger – und häufig unterschätzter – Fall. Ein klassisches RAG-System würde hier trotzdem eine Antwort generieren („halluzinieren“). Ein Reasoning-Modell hingegen:
- Versucht alternative Suchbegriffe (mehrere Iterationen)
- Prüft verwandte Dokumentkategorien
- Stellt fest: Das Dokument existiert nicht
- Meldet das explizit in der Antwort – und flaggt die Lücke
Damit entsteht ein direkter Rückkoppelungskreis zur Wissenspflege: Fehlendes Wissen wird zum konkreten Redaktionshinweis. Das Reasoning-Modell kann Wissenslücken aktiv identifizieren und den Pflegeprozess im Knowledge-Management-System triggern.
Der Agent-Loop: Wie das Modell wirklich „denkt“
Hinter dem Begriff Reasoning steckt eine technische Struktur, die als Agent-Loop bezeichnet wird. Das Modell arbeitet nicht linear, sondern in einer Werkzeugschleife – mit zwei möglichen Ausgängen: Erfolg mit vollständiger Antwort, oder expliziter Abbruch mit Meldung der fehlenden Information.
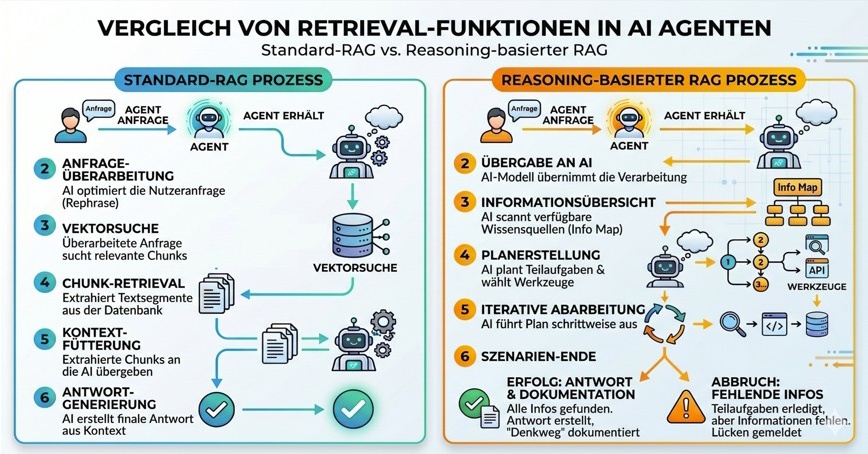
Diese Schleife kann je nach Komplexität 2 bis 10 Iterationen durchlaufen. Jede Iteration ist vollständig protokollierbar – was MCP von einem einfachen Kontext-Dump unterscheidet:
| Ansatz | Funktionsweise | Schwäche |
|---|---|---|
| Klassischer Kontext-Dump | Alle Dokumente auf einmal übergeben | Rauschen, hohe Kosten, veraltete Snapshots |
| MCP-basiertes Reasoning | Gezielter Abruf genau dann, wenn benötigt | – |
Der Vorteil ist dreifach: Präzision (kein irrelevantes Rauschen), Aktualität (jeder Abruf geht gegen die Live-Datenbank), Transparenz (vollständige Audit-Trail der genutzten Informationsquellen).
Was der Agent am Ende sieht
Der Output eines Reasoning-basierten Systems ist strukturiert und enthält immer mehr als nur eine Antwort:
Den Denkweg (Chain of Thought):
Jeder Analyseschritt ist dokumentiert. Der Agent sieht nicht nur die Antwort, sondern warum sie so lautet. Das schafft Vertrauen und ermöglicht Korrekturen.
Quellenverweise:
Jede Aussage ist mit Artikel-ID und Paragraph verknüpft. Der Agent kann auf Knopfdruck das Quelldokument direkt aufrufen.
Konfidenz-Hinweise:
Wenn das Modell unsicher ist (z.B. Dokument ohne gesetztes Ablaufdatum, oder zwei Dokumente mit ähnlichem aber nicht identischem Inhalt), markiert es das explizit.
Handlungsempfehlung:
Das Modell schlägt die nächste Aktion vor: „Gutschrift veranlassen“, „Fachbereich eskalieren“, „Kunden zurückrufen“.
Warum Reasoning nur mit gepflegtem Wissen funktioniert
Das Reasoning-basierten System ist so gut wie das Wissen, auf das es zugreift. Das ist keine Einschränkung – das ist die entscheidende Erkenntnis:
| Wissensproblem | Auswirkung auf Reasoning |
|---|---|
| Dokument fehlt | Teilfrage nicht beantwortbar, Lücke wird gemeldet |
| Dokument veraltet | Veraltete Antwort, wenn kein Ablaufdatum gesetzt |
| Widerspruch im Wissen | Modell erkennt ihn, kann nicht auflösen, eskaliert |
| Unklare Formulierung | Interpretation möglicherweise falsch, niedrige Konfidenz |
| Gut strukturiert & aktuell | Präzise Antwort mit Quellennachweis |
Reasoning ist damit nicht nur ein weiterer Use Case – es ist der Stresstest für alles, was im Wissensmanagement davor passiert ist. Vollständigkeit, Widerspruchsfreiheit und aktuelle Inhalte sind keine Qualitätsziele für den Redaktionsalltag. Sie sind die Voraussetzungen dafür, dass eine KI im Service wirklich denken kann.
Fazit
Reasoning verändert die Rolle der KI im Kundenservice grundlegend. Nicht mehr nur Suchen und Wiedergeben – sondern Analysieren, Verknüpfen, Schlussfolgern.
Das MCP-Protokoll ist dabei der technische Schlüssel: Es macht den Dokumentenabruf iterativ, transparent und auditierbar. Das Modell holt sich genau das Wissen, das es gerade braucht – aus der Live-Datenbank, nicht aus einem Snapshot.
Und die wichtigste Erkenntnis für alle, die KI im Service einsetzen wollen:
Das Reasoning-basierten System ist der Beweis, dass gutes Wissensmanagement kein Selbstzweck ist. Es ist die Grundlage dafür, dass KI wirklich denken kann.
Weiterführende Ressourcen
Weitere Artikel auf diesem Blog
- Reasoning in Large Language Models
- Reasoning basierte Wissensdatenbanken – ein Blueprint
- Reasoning in Wissensdatenbanken – Vor- und Nachteile
- Reasoning basierte GenAI-Wissensdatenbanken im technischen Service
Reasoning & Agent-Architekturen
- Anthropic: Claude – Tool Use & Agents
- Model Context Protocol (MCP) – Spezifikation
- ReAct: Synergizing Reasoning and Acting in Language Models (arXiv)
Hintergrundartikel
Schreibe einen Kommentar