
Der stochastische Charakter von Large Language Models ist jedermann heute hinreichend geläufig.
In den Projekten heißt das häufig, dass unzählige Testcases definiert werden und diese dann automatisiert häufig durchgetestet werden müssen, die Ergebnisse per LLM aufbereitet werden (LLM as a judge) und dann zur Analyse vorgelegt werden müssen.
Und dann fragt ein Anwender doch etwas, an was noch nie einer gedacht hat, und… da ist er, der Fehler. Und dann mag es sein, dass die Anwender das System ablehnen oder dass durch Tests & Korrekturen & Tests die Projekte einfach viel teurer und langfristiger werden, als das eingeplant war.
Man vergisst dabei gerne, dass eigentlich alle „normalen“ Ereignisse und Prozesse in unserem Leben stochastischer Natur sind. Und die Wahrscheinlichkeit eines Ereignisses ist nicht nur eine Eigenschaft meinetwegen der Maschine, des Werkzeuges, sondern natürlich auch der Nutzung.
Oder etwas drastisch formuliert: Abstürze mit modernen Verkehrsflugzeugen sind zum Glück, sehr, sehr selten. Das liegt aber eben auch daran, weil man mit ihnen nicht versucht, unter Brücken durchzufliegen oder andere waghalsige Manöver zu veranstalten, für die sie nicht gebaut sind.
Eigentlich geht es den LLMs auch nicht so viel anders. Und dennoch werden alle Fehler der Modelle irgendwie gleich behandelt. Und so scheitert dann manches Projekt daran, dass die Ergebnisqualität leider nicht passt. „83,4% ist eben nicht ausreichend für uns“.
Pauschalierungen sind schon im Alltag oft wenig hilfreich, zum Erreichen von Projektzielen sind sie noch weniger nützlich.
Plant und berücksichtig man die Komplexität der Aufgabe, dann hat man einen starken Hebel, um die Aufwände und die Ergebnisqualität vorhersehbar zu machen.
Denn tatsächlich können LLMs auch hundert Prozent verlässlich sein, wenn man sie einfache Aufgaben machen lässt. Forschungsergebnisse zeigen, dass die Verlässlichkeit der Aufgabenerfüllung von LLMs direkt (aber nicht linear) von der Aufgabenkomplexität abhängt. Natürlich hängt die bewältigbare Komplexität von der Modellleistungsfähigkeit ab, aber für alle Modelle gilt, dass die Verlässlichkeit ab überschreiten einer entsprechenden Komplexität rasch und nicht linear einbricht.
Das kann man sogar recht einfach selbst probieren
Nehmen wir zwei LLMs wie beispielsweise GPT 4o mini – ein eher einfaches Modell. Und Sonnet 4.6, das mit 3,00 $ pro 1 Mio Token auch nicht ganz günstig ist.
Wir laden den Vertragstext der Bedingungen eines Finanzangebotes in den Kontext. Wir verwenden also kein Chunking und keine Vektorsuche, da dies die Komplexität natürlich schwieriger kontrollierbar machen würde.
Und dann stellen wir den beiden Modellen einfach eine Frage nach irgendwelchen Eigenschaften dieses Finanzproduktes, Eigenschaften, die sich direkt einem der Paragraphen in dem Vertragstext entnehmen lassen.
Um die Verlässlichkeit etwas genauer beurteilen zu können als einfach nur „richtig“ oder „falsch“ lassen wir das System ausgeben, wie viele Paragraphen es zur Beantwortung der Frage benötigt hat. Das wird es uns nachher einfacher machen, das „Zusammenbrechen“ der Verlässlichkeit zeigen zu können.
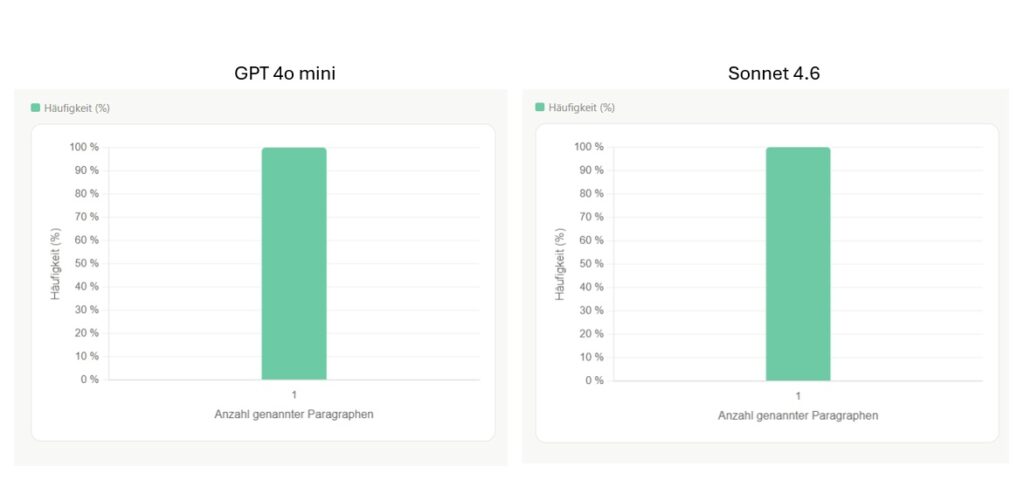
Aber bisher sieht alles sehr gut aus.
Wie wir der Auswertung entnehmen können, benötigen Sonnet 4.6 und GPT4o mini ganz stabil nur einen Paragraphen, um die Antwort zu generieren. Wir sind noch im verlässlichen Bereich beider Modelle.
Nun steigern wir die Fragekomplexität. Statt nach einer einfachen Eigenschaft des Finanzproduktes zu fragen, wird die Frage aus einem konkreten Kunden-Usecase heraus formuliert. Beispielsweise nach Kosten, Risiken und der Vorgehensweise bei einer vorzeitigen Rückgabe eines geleasten Objektes.
Da sieht das Ganze schon etwas anders aus.
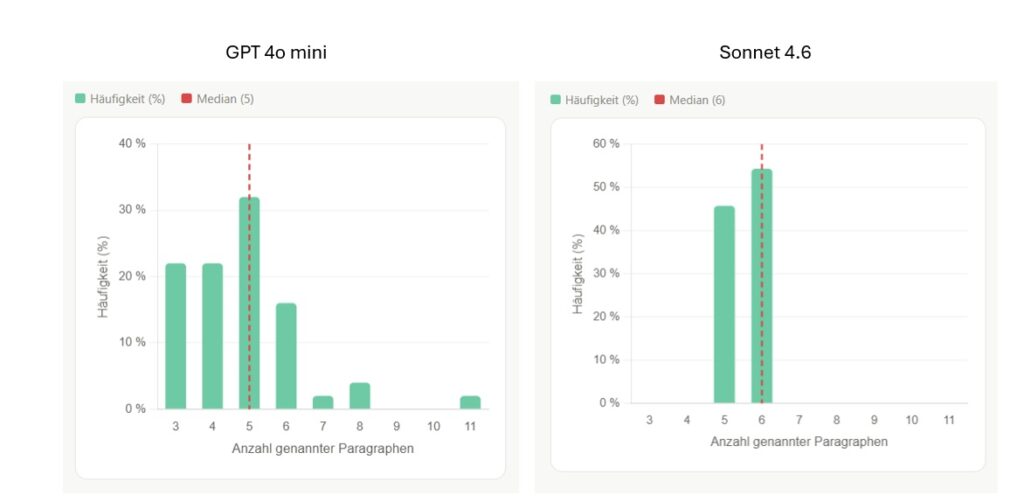
GPT 4o mini ist hier nicht mehr in der Lage, stabile Leistungen zu zeigen. In manchen Fällen werden nur 3 Paragraphen verwendet, in manchen 11. (Anmerkung: Das heißt nicht, dass die Antworten in gleichem Maße falsch sind. Auch das Zählen der Paragraphen ist ja eine „Aufgabenkomplexität“. Aber tatsächlich sind die Antworten hier nicht mehr sehr verlässlich). Sonnet schlägt sich hier noch besser und zeigt eine respektable Stabilität, die aber deutlich macht, dass auch Sonnet hier Grenzen erreicht.
Steigern wir die Komplexität weiter (beispielsweise ist das geleaste Objekt bei der Rückgabe auch noch beschädigt), dann ist für beide Modelle die Grenze der Verlässlichkeit erreicht.
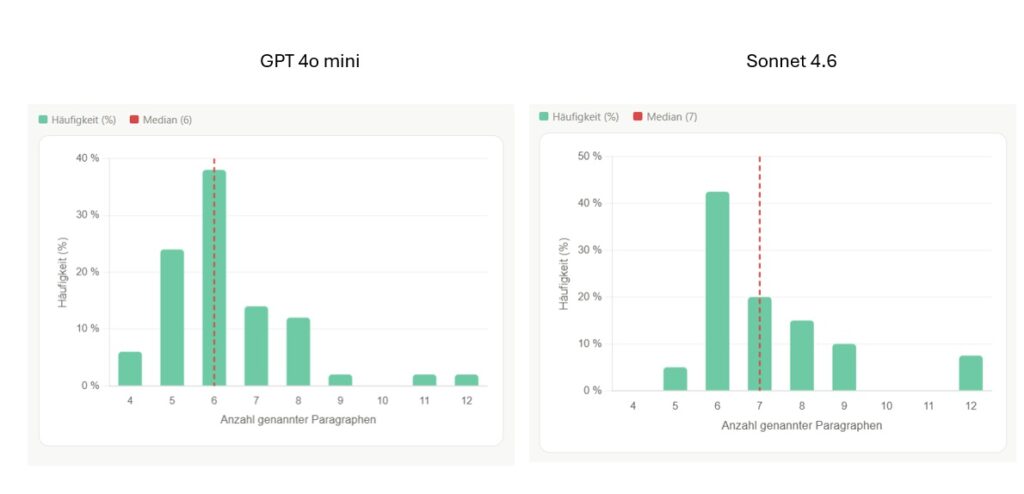
Welche Möglichkeiten bietet das für die Praxis?
Es wurde deutlich, dass die Aufgabenkomplexität und die Modellleistungsfähigkeit wesentliche Parameter sind, um die Verlässlichkeit eines AI Agenten zu regeln.
Beachtet man diesen Umstand nicht, dann macht das die oben angeführten Tests potentiell unüberschaubar. Denn man stellt fest, dass manche Aufgaben oder Fragen irgendwie nicht richtig in den Griff zu kriegen sind und gleichzeitig die Anzahl der Tests doch sehr hoch wird. Natürlich gibt es hier Automatisierungsangebote, dennoch steigt der Aufwand stark an.
Sind also beispielsweise 100% Verlässlichkeit gefordert, dann gibt es die Möglichkeit, die Aufgabenkomplexität so weit zu reduzieren, dass sie zu den Möglichkeiten des Modells passt. Das bedeutet, man muss Aufgaben- oder Fragenklassen definieren, die zulässig sind und andere entweder mit Unsicherheit beantworten oder ablehnen. Und es ist gar nicht so komplex, diese Frageklassen zu definieren, wenn man sich mit dem jeweiligen Themenraum beschäftigt. Jedenfalls ist es weniger Aufwand, als alle potentiellen Fragestellungen und Antworten für Tests zu erstellen.
Vielleicht einfach mal anhand eines Beispiels:
Vergleichsweise einfach sind immer Abfragen von Eigenschaften, die dem LLM direkt vorliegen.
Komplexer sind Abbildungsleistungen, wenn also die Frage des Anwenders z.B. Situationen oder Lebenslagen beschreibt, zu denen erst die verschiedenen Aussagen im Kontext zu analysieren und dann zusammenzufassen sind.
Und noch weiter steigt der Schwierigkeitsgrad, wenn Bewertungen, Vergleiche oder gar Vorgehensweisen aus den Inhalten abgeleitet werden sollen.
Stellen wir nun die Anforderung, dass nur die ersten beiden Klassen tatsächlich zugelassen sind, dann kann man zum einen die Systemparameter daran ausrichten. Und zum anderen hat man die Möglichkeit, für diese Frageklassen typische Vertreter zu definieren. Es ist dann ausreichend, diese Vertreter zu testen. Und zum anderen kann man die darüber hinausgehenden Anfragen einfach ablehnen oder „ohne Gewähr“ beantworten.
Statt also hunderter, in der Praxis oder in Tests gesammelte Fragen zu verwalten und zu testen lässt sich so über ein gezieltes, komplexitätsbasiertes Testdesign schlicht Aufwand sparen.
Ein kluges Berücksichtigen der Aufgabenkomplexität ist ein wesentlicher Baustein, um die Ergebnisse von AI Projekten vorhersehbar und erfolgreich zu machen.
Schreibe einen Kommentar