
Fragen richtig stellen ist durchaus eine Kunst – und die oft bemängelte Halluzinationsneigung von LLMs basiert in manchen Fällen einfach auf dem Problem, dass Fragen falsch gestellt werden.
Schauen wir uns an, warum es überhaupt zu solchen Problemen kommen kann.
Welche probleme gibt es
LLMs antworten mit dem „Wahrscheinlichsten“
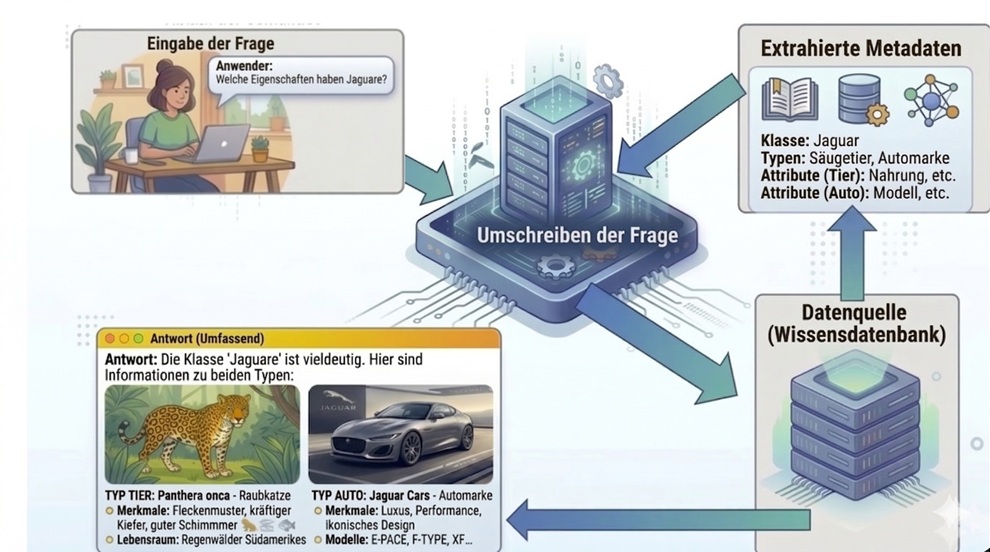
Fragt ein Anwender nach „Welche Eigenschaften hat ein Jaguar“, dann antwortet das System tendenziell mit den Eigenschaften der Großkatze. Dass auch die Fahrzeugmarke oder gar der legendäre E-Type gemeint sein könnte, geht aufgrund der geringeren Wahrscheinlichkeit unter.
LLMs kennen oft den Kontext nicht
Das ist auch in der menschlichen Kommunikation ein Problem. Aber Menschen kennen sich gegenseitig und können die Situation des Gegenüberstehenden oft besser einschätzen und wissen daher, „wo der Schuh drückt“. Hat man es gemeinsam eilig auf den Zug und ein Gruppenteilnehmer beginnt eine Diskussion, dann reicht unter den Beteiligten die Frage „kann das warten?“. Die Intention ist dann sofort klar. Für ein LLM wäre diese Frage nicht interpretierbar, solange es den Kontext nicht kennt – was die Regel sein dürfte.
LLMs können die Kommunikationsgewohnheiten von Menschen nicht einfach so kennen
In Customer Service Center fragen Anwender gerne nach „aktuelle Angebote“ – weil sie beispielsweise gewohnt sind, auf diese Frage eine Auflistung der neuen Tarife zu bekommen. Das kann das LLM nicht wissen und könnte auch eine Liste aller aktuell gültigen Angebote erstellen.
Menschen verwenden gerne falsche Begrifflichkeiten
Nehmen wir an, es gibt eine Software, die es per API möglich macht, Dokumente im Internet darzustellen. Nun hat ein Anwender eine Frage zu diesen technischen Möglichkeiten. In der Dokumentation steht die Funktionsbeschreibung bei der Schnittstelle – die der Anwender nicht benennen kann. Diese kennt Funktionen – die der Anwender nicht kennt. Dem Anwender ist nun nur auf der Webseite ein Verhalten aufgetreten, das er nun gerne ändern möchte. Aber er kann es nicht wirklich benennen. Fragt er mit dieser Frage das LLM, dann wird die Antwort oft falsch sein, da das LLM die Frage einfach nicht richtig zuordnen kann. Der Anwender spricht dann vielleicht von „Webseite“, „Text“ oder „Reihenfolge“, obwohl er eigentlich die Schnittstelle meint. Und das System schaut dann vielleicht an ganz anderer Stelle in der Dokumentation.
Wie kann man das Problem beheben?
Man ermöglicht Rückfragen!
Ein probates Mittel zur Optimierung der Antwortqualität sind multi-turn Dialoge, in denen die Mehrdeutigkeit der Frage analysiert wird und daraufhin Rückfragen zur Klärung erstellt werden.
Die Herausforderung ist dabei jedoch, wie das LLM feststellen kann, wann eine Anfrage uneindeutig ist. Da das System nicht alles zu verwendende Wissen in seinem Contextwindow haben kann und daher auf eine Suche angewiesen ist (also die übliche RAG Architektur), kann es auch die fehlende Eindeutigkeit einer Frage erst dann ermitteln, wenn es die Suche ausgeführt hat.
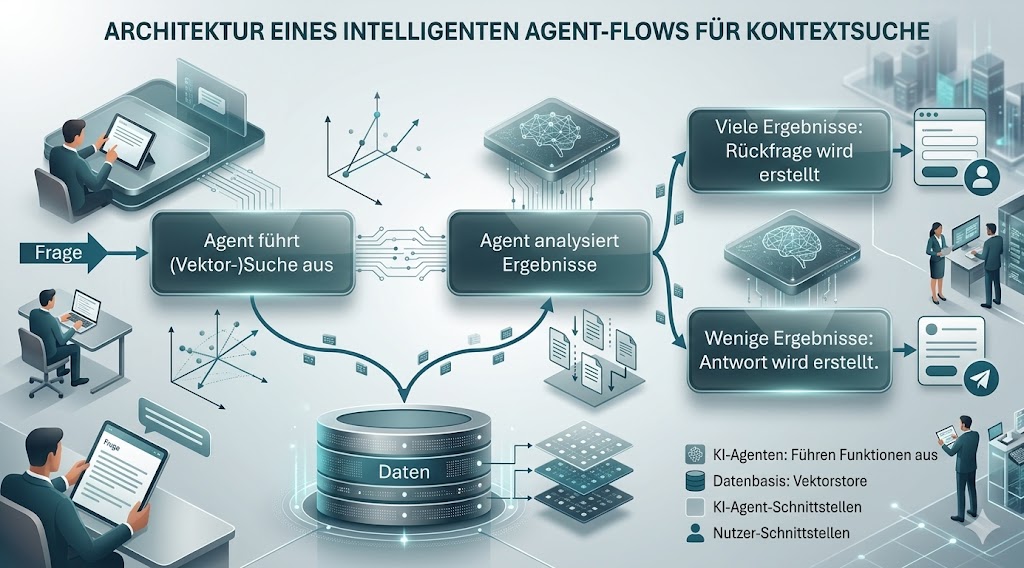
Eine typische Architektur kann dabei so aussehen, dass nach der Suche ein Agent im Agentflow eine Bewertung des Gefundenen vornimmt und dann das Ergebnis entweder an einen Agenten weitergibt, der eine Antwort gibt oder an einen, der Rückfragen stellt.
Hier ist dann ein Indiz für mangelnde Eindeutigkeit beispielsweise die zu große Ergebnismenge.
Man schreibt die Frage um
Eine zweite Möglichkeit: Man schreibt die Frage so um, dass das Modell die Frage besser versteht.
Dazu muss man den Eingangs-Agenten, der die Frage entgegennimmt mit entsprechendem Konzeptwissen versorgen. Das kann je nach Datenmenge so aussehen, dass der Agent wesentliche Fragenbeispiele hat, anhand derer er die Anfrage bewertet oder dass er eine Ontologie kennt, die er für die Bewertung der Frage verwendet. Da diese Ontologie oder die Anzahl der Fragenbeispiele groß sein können, kann das auch von einer Datenbank geladen werden.
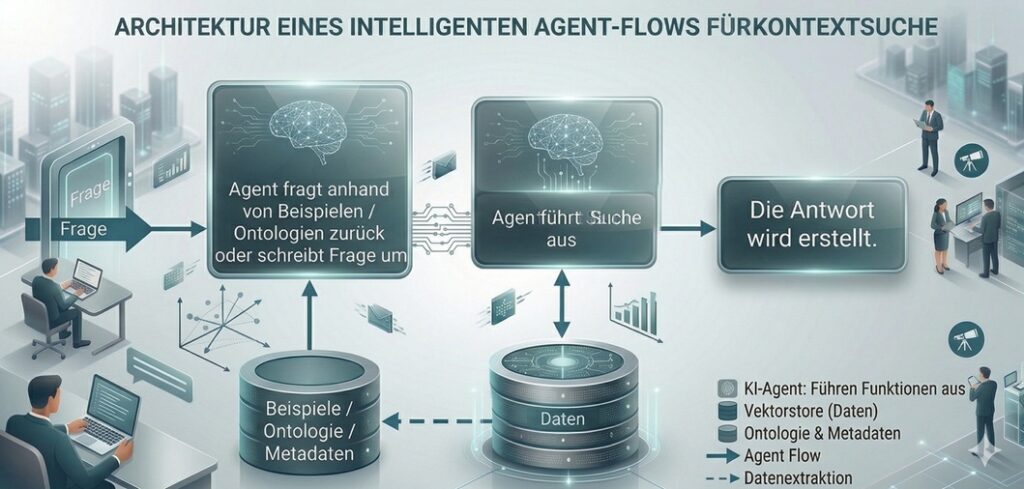
Mithilfe einer Ontologie ist es dann für das System möglich, eine Frage entsprechend zu bewerten bzw. zu klassifizieren.
Ein wesentlicher Vorteil einer Ontologie ist es, dass die Frage umgeschrieben werden und dem Anwender nochmals zur Überprüfung vorgelegt werden kann. Um nochmals das Beispiel mit der Internet-Schnittstelle anzusprechen:
Das System kann dann aus den Informationen in der Ontologie schlussfolgern, um welche eigentlichen Module der Software es wohl geht und die Software entsprechend neu schreiben. Das ermöglicht es dem Anwender zum Einen, die Frage nochmals zu überprüfen und zum anderen dem System, die Anfrage dann korrekt und mit einer passenden Terminologie auszuführen.
Woher bekommt man Metadaten?
Manchmal ist natürlich das Beschaffen oder Erstellen der Ontologie ein echtes Problem.
In unseren Praxisbeispielen konnten wir hier im öffentlichen Bereich auf eine klare Terminologie zurückgreifen. Da war die Beschaffung der Metadaten problemlos.
Geht es hingegen um technische Handbücher komplexer Systeme, dann ist das Ganze nicht mehr so einfach. Entweder man erstellt mit doch recht hohem Aufwand tatsächlich manuell eine solche Ontologie, oder man kann eine Ontologie per LLM aus technischen Handbüchern extrahieren. Diese automatisierte Möglichkeit funktioniert tatsächlich abhängig von der Dokumentenqualität ganz gut.
Die Modelle von Anthropic (Opus 4.6) haben hier in Tests bei uns am besten abgeschnitten.
Um das Prompt für die Generierung der Metadaten zu erstellen benötigt man jedoch Kenntnis der Hauptelemente des jeweiligen technischen Systems.
Zudem war es auch hier sinnvoll, die erstellte Ontologie manuell nochmal zu überprüfen.
Fazit
Es ist ein Risiko, dass auf eine falsch gestellte Frage eine fehlerhafte Antwort gegeben wird. Das intelligente Umschreiben der Frage mithilfe extrahierter Metadaten ist eine kluge Strategie, die hier weiterhilft.
Schreibe einen Kommentar