Reasoning basierte Wissensdatenbanken haben einige Vorteile (link), gerade im technischen Umfeld.
Um es einfach kurz zusammenzufassen: Eine Q&A basierte Wissensdatenbank ist wie eine Liste, in der alle Rechnungen des kleinen 1×1 hinterlegt sind:
1+1=2
2+2=4
3+3=6
und so weiter. Das sind ganz schön viele Einträge.
Eine Reasoning-basierte Datenbank kann rechnen. Damit spart man sich die Schreiberei! (Eine weitere Beschreibung findet man hier: Link)
Wie geht man vor, um eine solche Wissensdatenbank mal auszuprobieren. Natürlich empfehlen sich hier professionelle Wissensdatenbanken wie USU Knowledge Management. Möchte man jedoch mal einfach probieren, wie sich das anfühlt und ob die eigenen Dokumente überhaupt ausreichen, dann kann man sich auch einen kleinen Prototypen zusammenbauen.
Wir haben das mit Gemini 3.0 und mit Notebooklm ausprobiert – das funktioniert eigentlich ganz gut.
Wir hatten dabei zwei Testszenarien:
Einmal verwendeten wir unsere eigenen technischen Unterlagen und nutzten die Wissensdatenbank für Fragen, wie sie bei uns im Service angekommen sind.
Zum Anderen erstellten wir ein System, das Anwender durch die Erstellung eines Videos in Vids führten.
In beiden Fällen hat das Konzept sehr gut funktioniert.
Der Aufbau
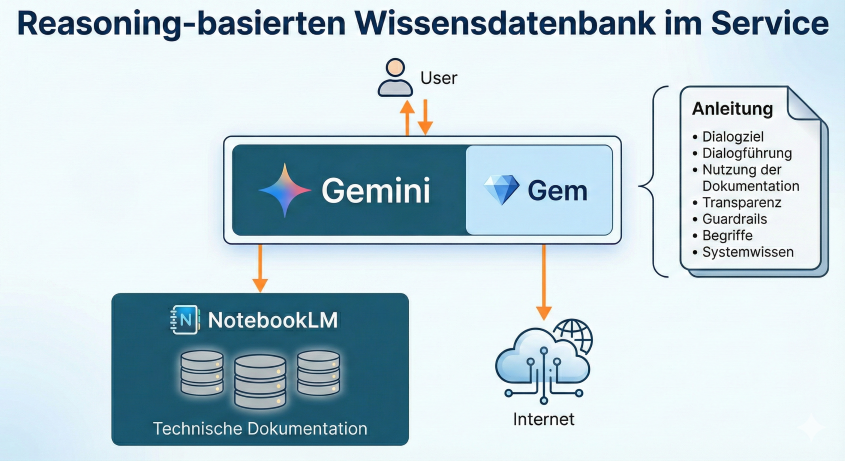
Grundsätzlich verwenden wir die in Gemini 3.0 angebotenen Gems.
Diese werden benötigt, um die Anweisungen für die Wissensdatenbank zu hinterlegen. Diese Anweisung wird dann permanent verwendet, die Inhalte in notebooklm je nach Fragestellung.
Man kann Gems direkt mit notebooklm verbinden. Dort hinterlegt man dann die technische Dokumentation, auf die man zugreifen möchte.
Fertig ist eine recht leistungsfähige Wissensdatenbank.
Notebooklm zeigt sich hier als ausgereiftes Tool. Der Zugriff auf die Inhalte ist nicht einfach nur eine Vector Search, wie das bei einem einfachen RAG Konzept der Fall wäre. Stellt man beispielsweise große Handbücher zur Verfügung, dann wird ein Phytonscript erstellt, das den Text des Handbuches auf relevante Stichworte scannt, um eine vernünftige Contextsize zu erreichen. Zudem kann man in der Anweisung im Gem hinterlegen, welche Dokumente für welche Fragen relevant sind. Dann entscheidet die KI das für die Frage zu wählende Dokument – das ist natürlich schlichten Chunks und einer Vektorsuche deutlich überlegen.
Generell stellen wir fest, dass ein einfaches RAG Konzept für Reasoning basierte Wissensdatenbanken nicht ausreicht. Daher ist der Einsatz von notebooklm hier schon sinnvoll.
Die Anweisung für das Gem
A und O des Ganzen ist natürlich das Prompt bzw. die Anweisung, die in dem Gem hinterlegt wird.
Dabei gibt es ein paar wesentliche Inhalte, auf die es ankommt:
Das Dialogziel muss klar sein. Geht es um eine Fehleranalyse und Behebung oder geht es um das Durchführen einer Aktion, bei der ein Anwender unterstützt werden muss.
Auch die Gesprächssituation und die Art der Gesprächsführung muss beschrieben sein: Geht es um eine Beratung am Telefon oder sitzt der Anwender selbst am System? Stellt der Anwender Fragen oder beschreibt Symptome oder ist von vorneherein klar, was das Ziel des Dialoges ist (beispielsweise das Erstellen eines Videos)? Entsprechend sind auch die Art der Fragen und die Art und Länge der Antworten zu beschreiben.
Hier muss das System auch wissen, welche Test- und Handlungsmöglichkeiten der Anwender überhaupt hat. Ist er Administrator oder Anwender oder gar Entwickler?
Soweit sind die Inhalte des Prompts die „üblichen“. Nun werden wir ein bisschen spezieller:
Das System muss wissen, welche Dokumentation vorliegt und welche Dokumente für welche Themen zu verwenden sind. Beispielsweise kann man darauf hinweisen, dass der User Guide für Handhabungsfragen verwendet werden soll (da folgt dann natürlich eine konkrete Liste. Bei uns waren das dann Themen wie „Dokumente editieren“ oder „Suche ausführen“), für Themen wie „Berechtigung vergeben“ oder „neue Workflows erstellen“ der Administration Guide.
Hier kann man beispielsweise auch auf Quellen im Internet verweisen. Im Falle von Vids haben wir einfach auf die Dokumentation im Internet verwiesen, was sehr gut funktioniert hat.
Wie bekannt besteht das Risiko, dass das System Falsches sagt. Das liegt in der Regel daran, dass es in den Dokumenten fehlendes Wissen vom System durch Annahmen ergänzt. Das ist nicht wirklich verhinderbar. Deswegen muss das System zu Transparenz aufgefordert werden. Es soll also immer deutlich machen, wie es denn zu seiner Antwort kommt und welches Wissen es dazu verwendet hat. Im Unterschied zu Q&A basierten Wissensdatenbanken darf und soll es jedoch sein eigenes Wissen einsetzen, gerne sogar Wissen aus dem Internet. Nur soll es den Einsatz des Wissens kennzeichnen.
Da das System auch etwas falsches sagen kann ist es wichtig, Guardrails festzulegen. Beispielsweise sind Maßnahmen, die die Systemlast, die Zugriffsrechte oder Kernfunktionen verändern könnten mit Warnhinweisen zu versehen. Aber das System darf diese Aussagen treffen. Sofern eine Lösung nicht funktioniert passiert nichts schlimmes – und wenn etwas passieren könnte, dann warnt das System entsprechen.
Und dann müssen in der Anweisung für das Gem noch das allgemeine, relevante Systemwissen stehen, das Wissen über die Anwendung oder das Produkt, zu dem es Lösungen finden soll. Im IT Fall wäre das zum Beispiel die Tatsache, dass es eine Browser-Anwendung ist, mit welcher Technik das Frontend erstellt wurde, welche relevanten Tools im Backend laufen etc.
Und man muss das System auf Zusammenhänge hinweisen, die besonders sind und sich nicht einfach aus der Dokumentation ergeben. Bei uns war das die Information, dass Dokumentenberechtigungen am Dokument hängen können und an den mit dem Dokument verbundenen Redaktionsaufgaben.
Das ermöglicht es dem System Fragen auch zum Beispiel zu http-Fehlermeldungen direkt im Zusammenhang mit dem Frontend zu beantworten. Und das System weiß, dass es sich seine Antworten zu Berechtigungsfragen aus den Anleitungen zu Dokumenten und zu Redaktionsaufgaben holen kann. Und damit ist es in der Lage, Antworten zu erstellen, die vorher niemand dokumentiert hatte.
Das hier beschriebene Wissen muss immer im Context stehen, unabhängig von der Suche. Diese Anweisung wird in der Praxis ganz schön groß. Daher sind hier leistungsfähige LLMs Voraussetzung.
Unsere Erfahrungen
Wir haben die oben angeführten Szenarien mal getestet. Für den Test unserer eigenen technischen Dokumentation verwendeten wir beispielhafte Tickets, so wie sie bei uns im Support eingingen.
Das hat in vielen Fällen sehr gut geklappt. In einigen Fällen war das System mit unseren umfangreichen Dokumenten überlastet und lief auf ein Timeout. Hier bleibt nur die Lösung, die Dokumente in kleinere Abschnitte zu unterteilen. Man muss auch anmerken, dass die Dokumente um die 400 Seiten aufweisen, was dann doch eine Herausforderung ist.
Besonders beeindrucken sind die multimodalen Fähigkeiten. Eine Fehlermeldung auf dem Bildschirm? Kein Problem, einfach an die Wissensdatenbank schicken und eine Lösung oder nähere Diagnose wird vorgeschlagen. Und als Diagnose hilft auch schon ein Screenshot der Browser-Konsole. Echt beeindrucken. Ohne dass zu dieser Fehlermeldung je ein Dokument erstellt worden wäre.
Auch bei dem Service-„Agenten“ für Vids waren die Erfahrungen extrem gut. Mit diesem Agenten an der Seite war es sehr einfach, Unterstützung in der Bedienung von Vids zu bekommen. Hier war diese Wissensdatenbank der Vids-Hilfe (die ja faktisch dieselben Dokumente nutzt) weit überlegen.
Die eigenen Lernerfahrungen konnte das System als Google Docs Dokumente generieren, die dann wieder in notebooklm abgelegt werden konnten. Das Lernen hat da ganz gut funktioniert.
Unser Fazit: Es ist wirklich einfach, einen Prototypen für eine reasoning-basierte Wissensdatenbank mal zu testen. Stellt sich heraus, dass das Prinzip im jeweiligen Umfeld funktioniert ist es dann ein einfacher Schritt, zu einer „richtigen“ Wissensdatenbank zu wechseln.
Schreibe einen Kommentar