Die MOtivation
Wissensdatenbanken waren in den letzten 20 Jahren echte Best Practice. Und doch: Es gibt immer noch viele Service Center, die kaum eine Wissensdatenbank verwenden. Es lohnt sich also ein genauerer Blick auf die Situation: So verzichten nur wenige Versicherungen, Finanzdienstleister oder Energieversorger in ihrem Kundenservice auf eine Wissensdatenbank. Hier findet man eine recht hohe Anwendungsdichte.
Die Situation zeigt sich jedoch anders, wenn man technische Service Center betrachtet. Hier sind Wissensdatenbanken oft eher Mauerblümchen. Richtig, es gibt absolut erfolgreiche Fälle, gerade auch im IT Service. Aber es gibt aber mehr eher nicht so erfolgreiche Fälle, gerade auch in mittleren und kleinen Unternehmen! So ist immer noch eine der häufigen Fragen bei Überlegungen zu Wissensdatenbanken im Service Center, ob denn auch „in den Tickets gesucht“ werden kann. Dabei zeigt der Blick in die Tickets, dass das meistens keine befriedigende Datenquelle ist. Der Aufwand für die Redaktion der Wissensdatenbank jedoch wird gescheut. Anders als beim Kundenservice bei Finanzdienstleistern oder auch Telko-Anbietern (jedenfalls bezogen auf die Tariffragen), bei dem die Redaktion letztlich auch „Hoheitsaufgabe“ ist.
Dieser Unterschied ist recht einfach erklärbar: In den genannten Service Centers geht es häufig um definierte Antworten: Eine Kulanzdefinition ist eben, wie eine Kulanzdefinition ist. Preise, Fristen und Laufzeiten von Angeboten sind, wie sie sind. Und das ist das zu beschreibende Wissen. Absolut umfangreich, aber definierbar. Und solange das Unternehmen keine neuen Regelungen herausbringt, muss das Wissen auch nicht aktualisiert werden.
Im technischen Service hingegen ist das Wissen eigentlich unbegrenzt und sein Detaillierungsgrad weitgehend von der Zielpersona abhängig. Während der eine Anwender nur die Information benötigt, wo beispielsweise eine Zertifikatsdatei zu erneuern ist, muss dem anderen für den gleichen Fall der Zusammenhang zwischen Fehlermeldung und Fehlerursache und technischen Hintergründen erläutert werden. Das Wissen entwickelt sich sogar unabhängig von der technischen Entwicklung des Serviceanbieters, da sich verwendete Basistechnologie ebenfalls entwickelt.
Diese hier beispielhaft genannten Unterschiede führen dazu, dass die üblichen „Q&A“-basierten Wissensdatenbanken im technischen Service recht aufwändig in der Anwendung sind. Wenn für jeden Fall und jede Persona ein Dokument zu erstellen ist, dann ist dies eine manchmal kaum zu erbringende redaktionelle Leistung.
Das hat uns dazu gebracht, uns mit reasoning-basierten GenAI-Wissensdatenbanken zu beschäftigen. Dieser Ansatz bietet die Möglichkeit, nur wenig Grundwissen zu hinterlegen. Das LLM kann daraus und aus seinem eigenen technologischen Wissen und eventuell einer Internetrecherche reichhaltige, anwendbare und gut erläuterte Anweisungen erstellen. Natürlich gibt es eine gewisse Fehlerwahrscheinlichkeit. Allerdings ist im technischen Service das Risiko dabei nicht ganz so groß. Ein fehlerhafter Lösungsversuch führt eben dazu, dass das Problem weiterhin bestehen bleibt. Es ist nur wichtig, manche Maßnahmen vorsichtig anzuwenden. Sich also an bestimmte Guardrails zu halten.
Reasoning-basierte GenAI-Wissensdatenbanken reduzieren den notwendigen Redaktionsaufwand drastisch. Oft können bestehende Handbücher und Dokumentationen verwendet werden. Statt also mehrere FTEs in die redaktionelle Leistung zu investieren, können reasoning-basierte GenAI-Wissensdatenbanken bestehendes verwenden.
Reasoning-basierte GenAI Wissensdatenbanken – das KOnzept
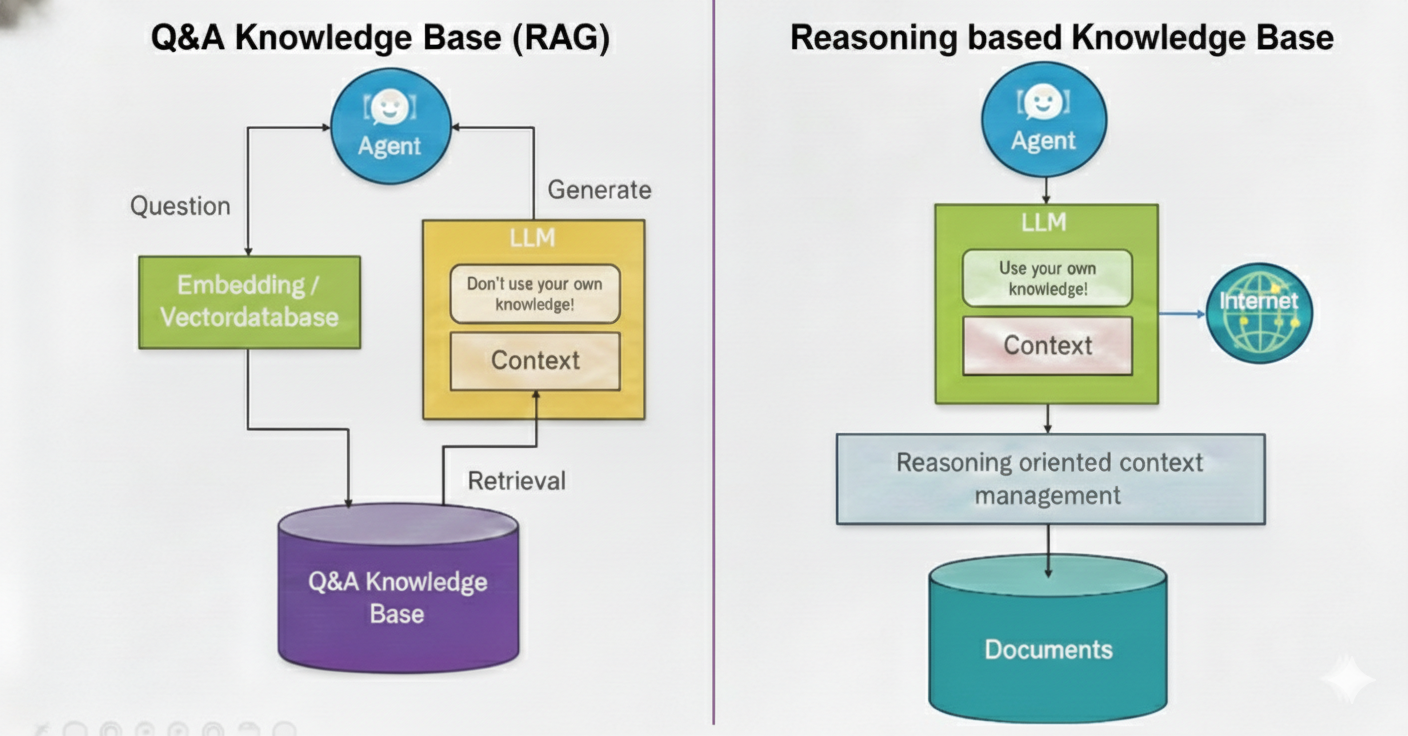
Q&A basierte Wissensdatenbanken setzen immer das bekannte „RAG Konzept“ ein. Dabei wird in der Regel auf eine vektorbasierte Suche gesetzt.
Wenn die Dokumente im Grundsatz eine Q&A-Struktur haben, dann kann dieser Ansatz auch funktionieren. In Fällen, in denen es auf Antwortqualität im Sinne einer genau einzuhaltenden Formulierung ankommt, gibt es tatsächlich auch kaum eine andere Möglichkeit, wenngleich eine vektorbasierte Suche dabei nicht zwingend ist.
Sollen jedoch die Reasoning-Fähigkeiten moderner LLMs verwendet werden um den Redaktionsaufwand drastisch zu senken, dann empfiehlt sich eine andere Architektur. In dieser wird bewusst der Context des LLMs so gesteuert, dass der Inhalt des Contextes den (immer noch begrenzten) Reasoning-Fähigkeiten des LLMs entspricht. Diese haben Schwierigkeiten damit, zu lange Reasoning-Ketten in großen Kontexten nachzuverfolgen, sie scheitern oft an Uneindeutigkeiten und Varianten – daher ist es wichtig, den Inhalt des Kontextes genau zu steuern, um eine hinreichende Antwortqualität zu erreichen.
Der Einsatz von RAG ist in diesen Fällen tatsächlich nicht genug. Einen detaillierten Artikel zu dem Einsatz von Reasoning und Zugriff auf Wissensdatenbanken findet man unter https://arxiv.org/pdf/2512.24601.
Wir sind uns sicher, dass Reasoning basierte GenAI Wissensdatenbanken den Einsatz von Wissensmanagement im technischen Service komplett ändern werden. Diese Architektur hat eine interessante Zukunft vor sich.
Die Vor- und Nachteile Reasoning-basierter Wissensdatenbanken findet man hier: Link
Einen Blueprint für einen Prototypen findet man hier: Link
Schreibe einen Kommentar